
Solved by:
Cr0wn_Gh0ul launched a new puzzle with a 1 Eth and 800 Matic prize recently. This involved airdropping matic NFTs and contracts to many addresses, similar to the one million matic NFTs he airdropped recently. This puzzle involved navigating the contracts, finding the NFTs, extracting text from the NFT images, and using the text as a private key. I will explain the process that went into solving this puzzle.
Title: You Got Mail!
Puzzle: 0xeF435c7042965dFA4Cac6be36D1c3CCCDd329A8A
Prize: 1 ETH + ? MATIC— T.Salem (@Cr0wn_Gh0ul) May 11, 2021
The Airdrop
This started with the tweet above, although some of us had already noticed the mass minting that was going on with NFTs on the "Recent" list on OpenSea. Using the Matic explorer, I was able to view the address that was creating all of the contracts:
Due to the amount of NFTs being created, it appeared to be causing problems for OpenSea and much like the similar Cr0wn NFTs, they were blacklisted and no longer viewable on OpenSea. With the address, I would still be able to view the transactions and NFTs. Sadly, I didn't get any screenshots of OpenSea before the write-up, but I can show you what it looked like linking it in Discord:
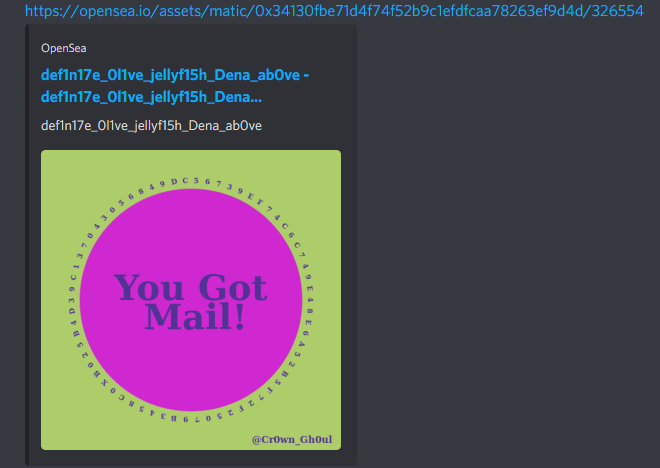
The NFT
The NFT was comprised of a randomly generated name, text in a polar circle around the center, and two randomly picked colors.

Given the length of the hex string in the circle and also the amount of NFTs being generated, it was likely that one of the NFT hex strings was the private key to the puzzle wallet. Unfortunately, it seemed like a million of these NFTs were going to be created.
In order to tackle this, we would need to download every image related to the NFT and extract the strings off of them at scale.
The Explorer
Unfortunately, maticvigil.com matic explorer had a strict WAF in front of it and loading it with Python requests was going to be next to impossible for the amount of requests I needed to make. We were stuck with what to do next until mattm found out we could query it with the api.covalenthq.com API.
Getting the Contracts
First we would query the transactions from the address:
https://api.covalenthq.com/v1/137/address/0xeF435c7042965dFA4Cac6be36D1c3CCCDd329A8A/transactions_v2/?no-logs=true&page-number=1&page-size=5000&key=
Then we would get the transaction details:
https://api.covalenthq.com/v1/137/transaction_v2/{0}/?&key=
And finally we could fetch the token names from the transaction:
https://api.covalenthq.com/v1/137/tokens/{0}/nft_token_ids/?&key=
This was condensed down into the following Python script:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 | import requests, json, urllib.request from multiprocessing import Pool ckey = "" def dedupe(lst): return list(dict.fromkeys(lst)) def getTransactions(url=""): if url == "": url = "https://api.covalenthq.com/v1/137/address/0xeF435c7042965dFA4Cac6be36D1c3CCCDd329A8A/transactions_v2/?no-logs=true&page-number=1&page-size=5000&key=" r = requests.get(url) txArr = [] data = json.loads(r.text) for tx in data["data"]["items"]: txArr.append(tx["tx_hash"]) return txArr def getCr0wn(name): url = "https://cr0wngh0ul.s3.us-east-2.amazonaws.com/{0}.json".format(name) r = requests.get(url) return json.loads(r.text) def getSender(tx): url = "https://api.covalenthq.com/v1/137/transaction_v2/{0}/?&key=".format(tx) r = requests.get(url) return json.loads(r.text)["data"]["items"] def getToken(address): url = "https://api.covalenthq.com/v1/137/tokens/{0}/nft_token_ids/?&key=".format(address) r = requests.get(url) return json.loads(r.text)["data"] def getSenderAddress(tx): senders = getSender(tx) for sender in senders: events = sender["log_events"] for event in events: if event["sender_address"] != "0x0000000000000000000000000000000000001010": return event["sender_address"] def getSenders(txArr): senders = [] for tx in txArr: senderAddresses = getSenderAddress(tx) senders.append(senderAddresses) return dedupe(senders) def getContracts(senders): contracts = [] for sender in senders: tokenData = getToken(sender) for item in tokenData["data"]["items"]: if item["contract_name"] not in contracts: contracts.append(item["contract_name"]) return dedupe(contracts) def getContractName(tx): senderAddress = getSender(tx)[0]["log_events"][1]["sender_address"] token = getToken(senderAddress) name = token["items"][0]["contract_name"] return name def getImg(name): url = "https://cr0wngh0ul.s3.us-east-2.amazonaws.com/{0}.png".format(name) print("Saving: {0}".format(name)) urllib.request.urlretrieve(url, "images/{0}.png".format(name)) def poolRoutine(tx): try: name = getContractName(tx) getImg(name) except: print("Failed: {0}".format(tx)) return if __name__=='__main__': txArr = dedupe(getTransactions()) print("Total tx: {0}".format(len(txArr))) pool = Pool(processes=10) pool.map(poolRoutine, txArr) |
Although a metric ton of NFTs were made, they were not all unique. After running through this entire list, we were able to dump 2609 unique NFT images.

Getting the text out
When faced with text in an image, we have a few options:
- Optical Character Recognition (OCR) - Programmatic way to extract text from images. Downsides: can be hard to train, images need to be clean and well formatted.
- Mechanical Turk - Pay people to write the text out. Downsides: cost money, no guarantee for accuracy.
- Type it yourself. Downsides: typing it yourself.
The clear winner is starting with OCR. The first issue we run into is that the text is circular and we will not be able to trivially train the characters. Before we can even consider going through OCR, we need to find a way to extract the text out into a straight line that is uniform across all 2609 images.
We have two options for this, that I know of:
- Pick a starting x,y coordinate in the image and height, width to crop to pull each letter. For each of the 66 characters, we need to rotate the image to ensure that the characters are all concatenated with the same rotation.
- Since all of the images are the same height, text is in the same position, and middle circle is always the same size, we can try to run it through a depolarization filter. This is a fairly standard filter that exists in a lot of image libraries such as ImageMagick, Photoshop, etc.
I don't want to dive too deep into the depolar because that was about an hour of effort that I did not document much. But here is an example of passing it through ImageMagick with depolar filter.
Command:
convert test3.png -virtual-pixel Black -set option:distort:scale 4 -distort DePolar -1 -roll +60+0 -virtual-pixel HorizontalTile -background Black -set option:distort:scale .25 polar.png
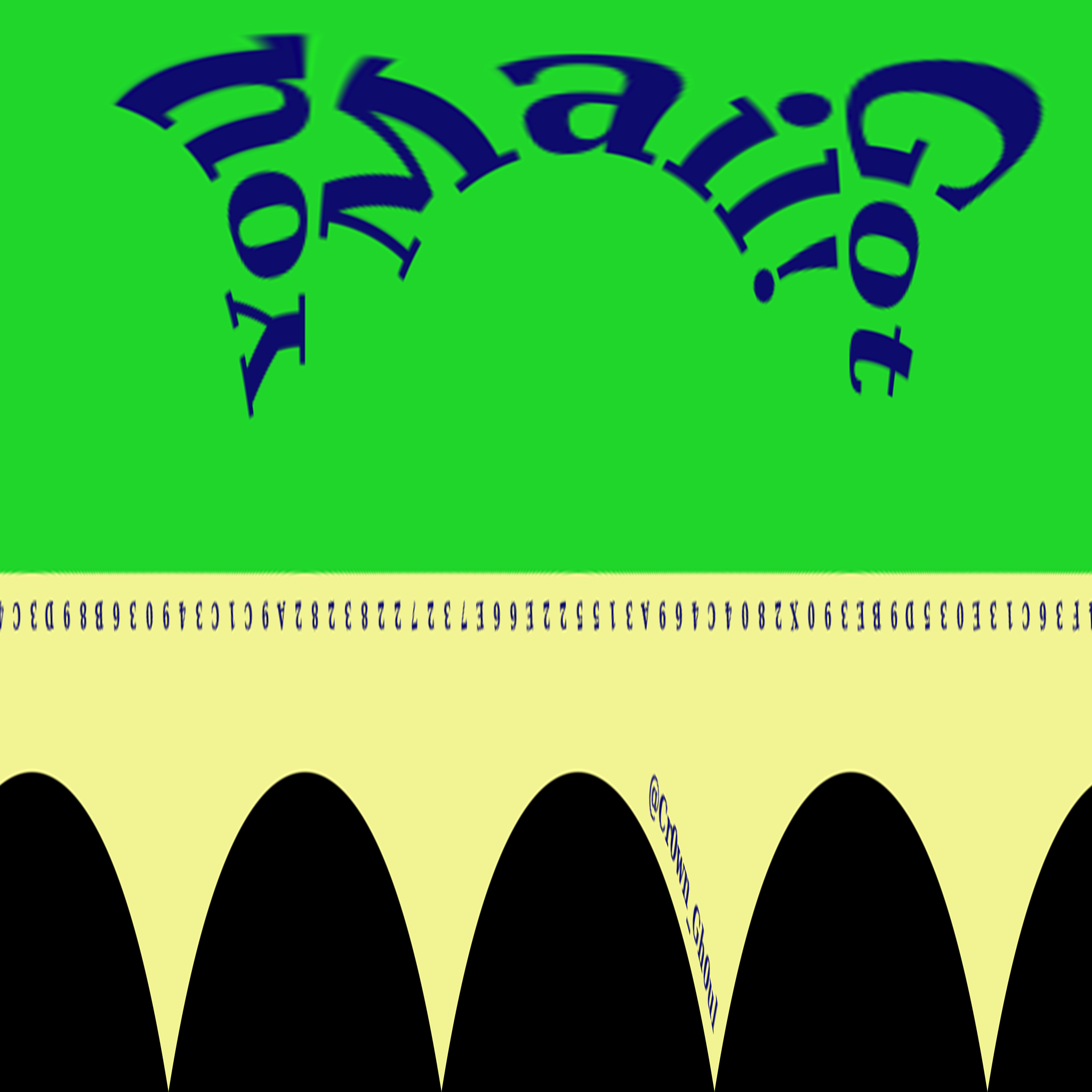
Unfortunately, this was a bit stretched and it was hard to determine where (or even how) to shift the text so it did not get cropped out. I decided to pursue a Python PIL approach with the rotations instead.
The first problem we face with Python PIL is figuring out where we start, given that the circular text is always started in different positions. So we attempt to extract at 244,40 with the height/width of 20,20 or 25,25.
Case A
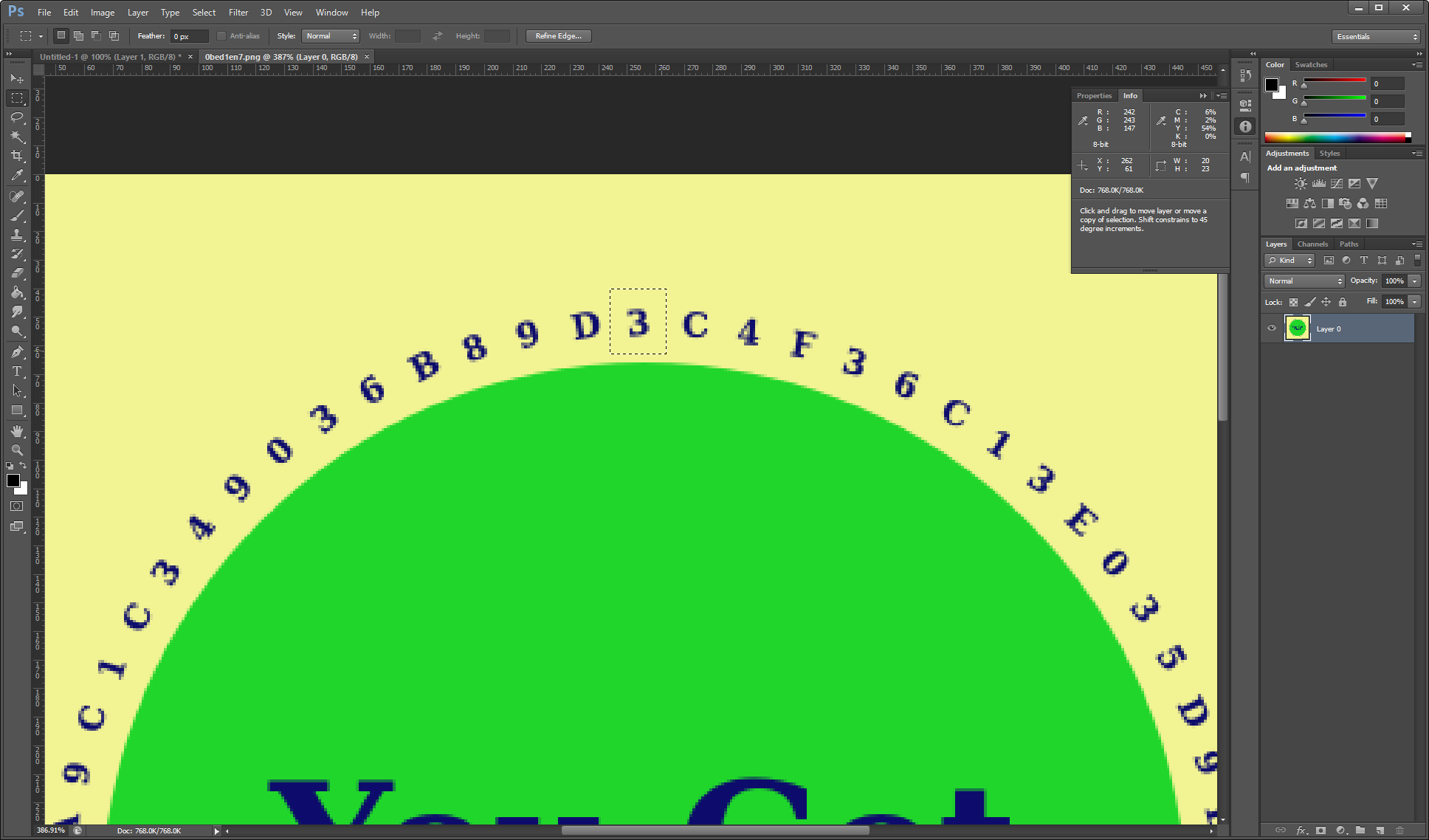
Case B
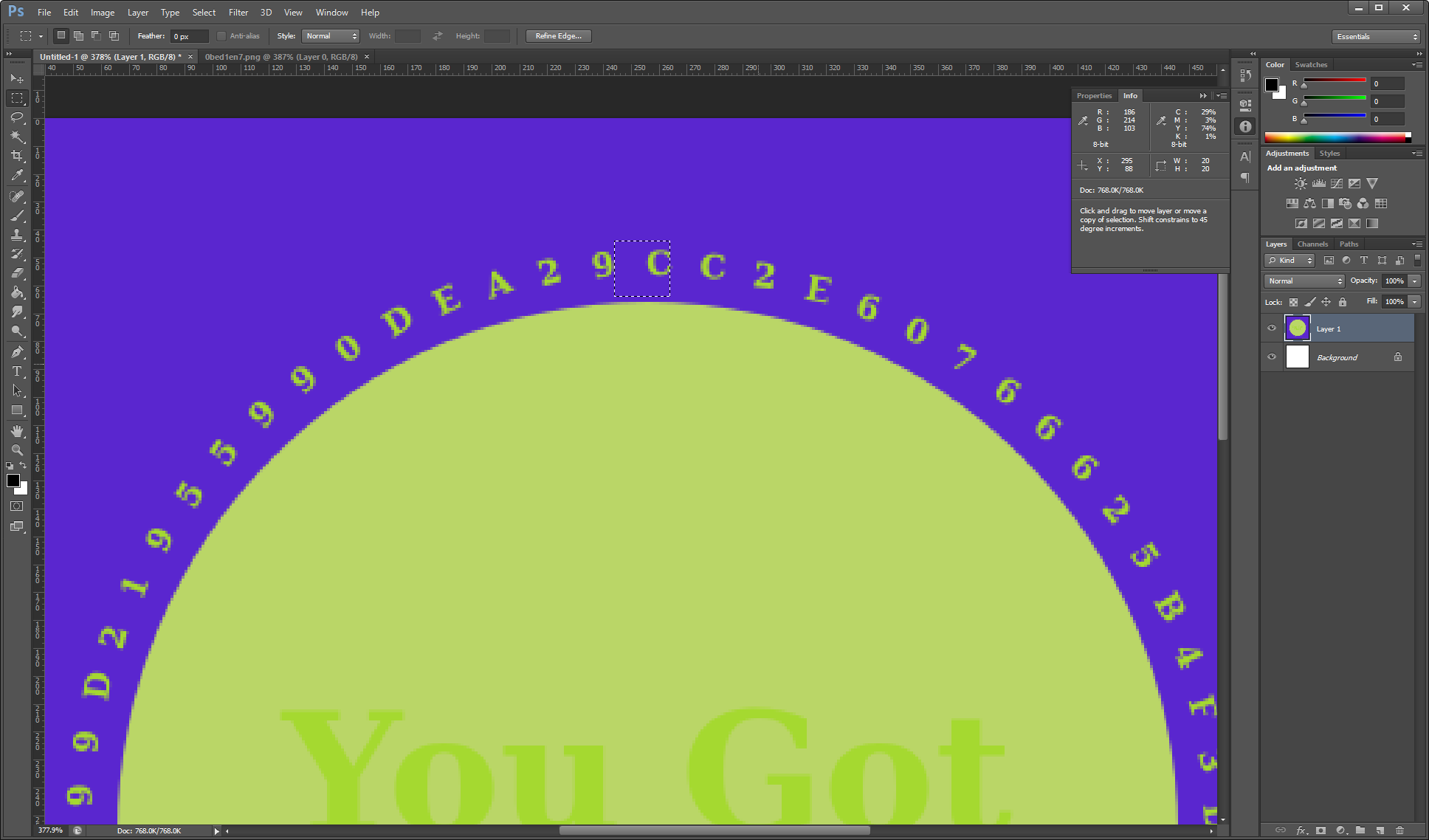
As you can see, there was no guarantee of a good starting position. Rotating the images manually in Photoshop, it was determined that the following approach had to be taken:
Output 1:
- Perform an initial rotation of 0
- Rotate the image every 15.45 degrees for each character
Output 2:
- Perform an initial rotation of 25
- Rotate the image every 5.45 degrees for each character
This was unfortunate because now we have doubled our image data, but it was the only way we could find a way forward quickly. This resulted in an image that looked like the following:
![]()
Now that we had letters extracting out, we can concatenate them together:
![]()
This is a good start, but when you try to use OCR to extract text from images, you will learn quickly that the best results is to contrast the image as much as possible and reduce it to two colors if possible.
Originally I tried to detect the background image color then replace any color not the background into white. This did not work well because of anti-aliasing. Then I tried to use PIL's filter grayscaling and autocontrast. This had decent results, but due to the random colors being selected, some images were still somewhat gray on gray which would not work well.
xEHLE came up with the idea of using numpy:
- Delete two color channels
- Threshhold cutoff for if a pixel should be white or black
- Invert if bg is white
This had a perfect result where all images would come out looking like this:
![]()
Here is what the final script looked like:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 | import pytesseract from multiprocessing import Pool from PIL import Image, ImageEnhance, ImageFilter, ImageOps from os import listdir from os.path import isfile, join import numpy as np pytesseract.pytesseract.tesseract_cmd = 'C:\\Program Files\\Tesseract-OCR\\tesseract.exe' def getCropPositions(position): cropSizeHeight = 15 cropSizeWidth = 20 cropPosStartX = 250 cropPosStartY = 45 cropPosEndX = cropPosStartX+cropSizeWidth cropPosEndY = cropPosStartY+cropSizeHeight return { "startX": cropPosStartX, "startY": cropPosStartY, "endX": cropPosEndX, "endY": cropPosEndY } def recolor(img2): bgColor = getBgColor(img2) rgb_im = img2.convert('RGB') pixels = rgb_im.load() for i in range(img2.size[0]): for j in range(img2.size[1]): r,g,b = pixels[i,j] r2,g2,b2 = bgColor if r != r2 and g != g2 and b != b2: pixels[i,j] = (0,0,0) return rgb_im def getBgColor(img): rgb_im = img.convert('RGB') r, g, b = rgb_im.getpixel((1, 1)) return(r,g,b) def getOCRText(file): text = pytesseract.image_to_string( Image.open(file), lang="English", config="--psm 4 --oem 3 -c tessedit_char_whitelist=0123456789ABCDEFX" ) return text def getLetter(image, position, type=1): cropPositions = getCropPositions(position) img = Image.open("images/{0}".format(image)) #img = recolor(img) if type == 1: baseRot = 0 posRot = 15.45 else: baseRot = 25 posRot = 5.45 img = img.rotate((baseRot+(5.45*position)), resample=Image.BICUBIC) img = img.crop(( cropPositions["startX"], cropPositions["startY"], cropPositions["endX"], cropPositions["endY"] )) width, height = img.size img = img.resize((width*5, height*5), resample=Image.BICUBIC) img_arr = np.array(img, np.uint8) img_arr[::, ::, 0] = 0 img_arr[::, ::, 2] = 100 img = Image.fromarray(img_arr) thresh = 85 fn = lambda x : 255 if x > thresh else 0 img = img.convert('L').point(fn, mode='1') if img.getpixel((1, 1)) == 0xff: img = img.convert('L') img = ImageOps.invert(img) return img def get_concat_h(im1, im2): dst = Image.new('RGB', (im1.width + im2.width, im1.height)) dst.paste(im1, (0, 0)) dst.paste(im2, (im1.width, 0)) return dst def makeStringImg(fileName, type=1): stringDir = "./strings" test = Image.new('RGB', (20, 20*5), (0, 0, 0)) for x in range(0,66): newImg = getLetter(fileName, x, type) if x == 0: newImg = get_concat_h(test, newImg) else: newImg = get_concat_h(oldImg, newImg) oldImg = newImg newImg = get_concat_h(oldImg, test) newImg.save('{0}/{1}-{2}'.format(stringDir, type, fileName)) def getImages(mypath="./images/"): images = [f for f in listdir(mypath) if isfile(join(mypath, f))] return images def getOCRImages(mypath="./strings/"): images = [f for f in listdir(mypath) if isfile(join(mypath, f))] for image in images: text = pytesseract.image_to_string( Image.open('{0}/{1}'.format(mypath, image)), lang="English", config="--psm 4 --oem 3 -c tessedit_char_whitelist=0123456789ABCDEFX" ) print("Test: ", text) exit() def makeStrings(image): try: makeStringImg(image, 1) makeStringImg(image, 2) print('{0} finished'.format(image)) except: print('{0} failed'.format(image)) def testStrings(): makeStringImg("0bl1ged_gray_jackal_57evena.png", 1) makeStringImg("0bl1ged_gray_jackal_57evena.png", 2) makeStringImg("0bed1en7.png", 1) makeStringImg("0bed1en7.png", 2) # getImages() # makeStringImg("0range_red_7aran7ula_Darby.png", 1) # makeStringImg("0range_red_7aran7ula_Darby.png", 2) if __name__=='__main__': images = getImages() pool = Pool(processes=10) pool.map(makeStrings, images) |
The resulting images were good enough to start extracting text with an OCR library, but not without its own problems!
Reading the text
How do you get text out of an image? There is a ton of research and tools that exist for OCR nowadays. These libraries are easy to install and can be imported easily as libraries into most programming languages. There are also toolkits that exist to help you train images into character sets.
I started with the following:
- Tesseract/pyTesseract
- jTessBoxEditor
jTessBoxEditor is a Java applet that lets you create box images from fonts or images. This is really useful if you know the font you are working with. In this case, it was either Georgia or Helvetica. I did not have any luck using either of these, so I tried to create my own box. It looks like this:
I must have spent four hours on this with no luck. I don't know if I was using it wrong or what was going on, but I was getting no results out of this. I eventually decided to pivot over to Google Cloud's Vision OCR.
The initial results were good! We were getting extracts out, but some of the characters were unicode from European character sets. It was not until we discovered that you could specify a specific charset language did we get clean strings out. This was really interesting to explore, but there is not much to really show other than the Python script:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 | import requests, json, base64, io import binascii from multiprocessing import Pool from os import listdir from os.path import isfile, join def getExtract(imageData): url = "https://content-vision.googleapis.com/v1/images:annotate?alt=json&key=" r = requests.post(url, headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0", "Accept": "*/*", "Accept-Language": "en-US,en;q=0.5", "Accept-Encoding": "gzip, deflate", "X-Clientdetails": "", "Authorization": "", "Content-Type": "application/json", "X-Requested-With": "XMLHttpRequest", "X-Javascript-User-Agent": "apix/3.0.0 google-api-javascript-client/1.1.0", "X-Origin": "https://explorer.apis.google.com", "X-Referer": "https://explorer.apis.google.com", "X-Goog-Encode-Response-If-Executable": "base64", "Origin": "https://content-vision.googleapis.com", "Referer": "", "Te": "trailers", "Connection": "close" }, json = { "requests": [{ "features": [{ "type": "TEXT_DETECTION" }], "image": { "content": imageData }, "imageContext": { "languageHints": [ "en" ] } }] }) # json = {"requests":[{"features":[{"type":"TEXT_DETECTION"}],"image":{"source":{"imageUri":str(imageUrl)}}}]} return cleanText(json.loads(r.text)["responses"][0]["fullTextAnnotation"]["text"]) def cleanText(text): # lower text = text.lower() # replacements replacements = [ [" ", ""], ["\n", ""], ["o", "0"], ["в","b"], ["с","c"], ["з","3"], ["o","0"], ["о","0"], ["х","x"] ] for replacement in replacements: text = text.replace(replacement[0], replacement[1]) # shift textStart = text.find("0x") before = text[:textStart] after = text[len(before):] text = after+before # ensure no extra newline was added text = text.replace("\n", "") return text def getImages(mypath="./strings/"): images = [f for f in listdir(mypath) if isfile(join(mypath, f))] return images def getImageContent(file, path="./strings"): path = "{0}/{1}".format(path,file) with io.open(path, 'rb') as image_file: content = image_file.read() return base64.b64encode(content).decode('UTF-8') def poolRoutine(image): try: imageData = getImageContent(image) extract = getExtract(imageData) extract = extract.encode('utf-8') print("{0} success: {1}".format(image,extract)) except Exception as e: print("{0} failed: {1}".format(image,e)) images = getImages() for image in images: poolRoutine(image) |
From this I was able to get 5198 results out, even though we knew that at least half of them were going to have garbage outputs due to the faulty start rotations. You can view the full list of extracts here:
And finally, since we assume that these are private keys for the prize wallet, we use the web3 library to go through and see if any of these private keys are a hit against the prize wallet address: 0xeF435c7042965dFA4Cac6be36D1c3CCCDd329A8A
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | import web3 def tryPkey(pkey): account = web3.eth.Account.privateKeyToAccount(pkey) if account.address.lower() == "0xeF435c7042965dFA4Cac6be36D1c3CCCDd329A8A".lower(): print("Found: {0}".format(pkey)) pkeys = [] for pkey in pkeys: try: tryPkey(pkey) except: continue |
Running this script ....
puzzle@li158-114:/home/puzzles/cr0wn# python3 wallet.py Found: 0xc3fb42759e4f802a75fb76bbcccd54b9d9751bb30709f7cbe95a21f0339058d1
Boom! The private key was found for the puzzle prize wallet. This turned out to be the following image:
5pare_c0ffee_cephal0p0d.png

The extract:
Overall this was another fun puzzle from cr0wn that was not without some insane frustrations and hurdles to overcome. This is one of my favorite aspects of a cr0wn puzzle, there is always something new for me to learn and they tend to be a blend of traditional security CTF puzzles and also what we see from the crypto puzzle scene.
Give @cr0wn_gh0ul a follow and make sure to check out his future puzzle drops.